Kui olete IT-spetsialist, siis teate, et OCR tähistab optilist märgituvastust. Ja teate ka seda, et Adobe OCR ei tunne teksti ära. Kuid te ei pruugi teada, kuidas seda probleemi lahendada. Adobe OCR-i teksti tuvastamiseks võite proovida mõnda asja. Esimene asi, mida saate proovida, on Adobe Acrobati tarkvara värskendamine. Mõnikord võib probleemi lahendada lihtsalt tarkvara värskendamine. Kui tarkvara värskendamine ei tööta, võite järgmisena proovida tuvastuskeelt. Selleks avage Adobe Acrobat, klõpsake 'Redigeeri' ja seejärel 'Eelistused'. Sealt klõpsake 'Keel' ja seejärel 'Tuvastamine'. Lõpuks valige keel, mida soovite tuvastamiseks kasutada. Kui tuvastuskeele muutmine ei tööta, võite järgmisena proovida OCR-i sätteid. Selleks avage Adobe Acrobat, klõpsake 'Redigeeri' ja seejärel 'Eelistused'. Sealt klõpsake 'OCR' ja seejärel 'Settings'. Lõpuks muutke seadeid, et näha, kas see lahendab probleemi. Kui olete kõiki neid asju proovinud ja Adobe OCR ikka veel teksti ära ei tunne, võib probleem olla teie PDF-failis. Kui see nii on, peate abi saamiseks ühendust võtma Adobe klienditoega.
Optiline märgituvastus (OCR) võib olla parem kui viilutatud leib neile, kes peavad teisendama tekstileheküljed redigeeritavaks tekstiks. võib-olla on teil arvutisse skannitavaid tekstilehti, mis tuleb nüüd redigeeritavasse vormi teisendada. Võib-olla pole tippimiseks piisavalt aega või on lihtsalt liiga palju aega tippimiseks. Noh, optiline märgituvastus aitab just seda. Saate lehekülgi arvutisse skannida ja rakendusega avada Adobe Acrobat ja proovige teksti tuvastamiseks ja redigeeritava versiooni andmiseks kasutada OCR-funktsiooni. Niipea kui oled võidutantsu tegemas, saad veateate Acrobat ei saanud sellel lehel OCR-i teostada, kuna see leht sisaldab kuvatavat teksti.
Adobe OCR ei tunne teksti ära

Acrobat Professionalil on OCR-funktsioonid, mis võimaldavad salvestada skannitud dokumente RTF- või Microsoft Wordi dokumentidena, nii Doc kui ka Docx. Võib juhtuda, et avate dokumendi Adobe Acrobat Professionalis ja näete teksti, kuid Acrobat annab vea. Acrobat ei saa OCR-i kasutada. See võib olla tingitud mitmest põhjusest.
- Renderdatud/redigeeritav tekst
- Moonutatud või udune allikas
- Kehv originaal
- Graafika ja vormid
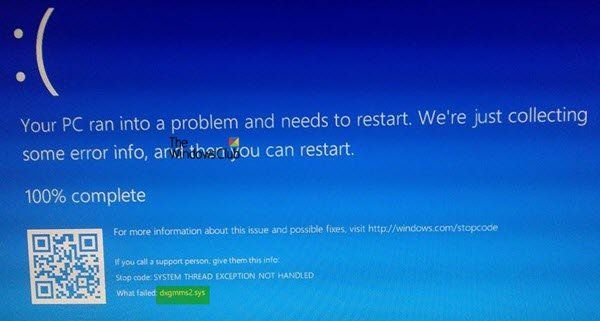
Acrobat ei saanud sellel lehel OCR-i teostada, kuna see leht sisaldab kuvatavat teksti.
1] Renderdatud/redigeeritav tekst
Esitatav tekst on redigeeritav tekst, mis on failis, mille jaoks soovite märgituvastust teostada. Acrobat ei saa OCR-i teostada dokumendile, mis sisaldab kuvatavat teksti. See on OCR-i skannimise tõrke kõige vähem ilmne põhjus, sest eeldame alati, et OCR-iga peaks skannima ka loetavat teksti.
Vastus:
Kui see on probleem, saate veaga toime tulla kahel viisil.
- Proovige hankida koopia dokumendist, millel pole kuvatavat teksti.
- Teisendage PDF TIFF-iks, seejärel tagasi PDF-iks ja proovige uuesti OCR-i.
PDF-i teisendamiseks TIFF-vormingusse avage see Acrobatis ja valige Fail ja seejärel Salvesta nimega. Kui ilmub dialoogiboks Salvesta nimega, valige loendist Failitüüp TIFF (*.tif, *.tiff). Määrake koht, kuhu soovite faili salvestada, seejärel klõpsake nuppu Salvesta. Acrobat salvestab PDF-dokumendi iga lehekülje eraldi järjestikuse numbriga TIFF-failina. Seejärel avate kõik TIFF-failid ja kasutage nende tuvastamiseks Acrobati.
Kui soovite dokumendid üheks liita, tehke järgmist.
- Avage Acrobat, valige Fail siis Looge PDF siis Mitmest failist .
- Vali Sirvige iga PDF-faili valimiseks ja lisamiseks. Korraldage failid nii, nagu soovite, et need uues PDF-is kuvaksid.
- Vali HEA .
2] Moonutatud või udune allikas
Hägune dokument
skype'i veebikaamerat kasutab mõni muu rakendus
Teine põhjus, miks Acrobat ei saa dokumendi OCR-i teostada, on selle madal eraldusvõime. Madala eraldusvõimega dokumendid võivad muutuda uduseks ja Acrobat ei suuda neid märgituvastust teostada.
Vastus:
Hankige kõrge eraldusvõimega dokumendi allikas. Kui skannite paberdokumenti, reguleerige skanneri eraldusvõimet nii, et see skanniks kõrgema eraldusvõimega.
moonutatud dokument
Acrobat ei pruugi korralikult joondatud teksti tuvastada. Dokument ei pruugi olla õigesti skannitud, nii et Acrobat ei saa sellel tähemärgituvastust teostada.
Vastus:
Enne skannimise alustamist veenduge, et paber, millele skannite, on tasane. Moonutatud dokumendi saate ka Photoshopis avada ja sirgendada. Siin on postitus, mis näitab teile, kuidas Photoshopis sirgendamise tööriista kasutada. See tööriist aitab teil skannitud dokumenti enne Acrobatis OCR-i tegemist sirgendada.
3] Halva kvaliteediga originaal
Kui lähtematerjal on halva kvaliteediga, näiteks faks, ei pruugi Acrobat seda õigesti tuvastada. Seejärel peate püüdma saavutada paremat kvaliteeti või riskima väljundi korrigeerimisega.
Vastus:
Hankige OCR-i jaoks parima kvaliteediga allikas. Kui teil on ainult madala kvaliteediga dokument, peate võib-olla käivitama optilise tekstituvastuse ja lootma, et vähemalt osa sellest tuvastatakse, ning seejärel täitma puuduvad osad.
4] Graafika ja kujundid
Graafikat ja kujundeid segavaid dokumente Acrobatis OCR-i ei tehta. Acrobatiga OCR-i jaoks kasutatavad dokumendid ei tohi sisaldada graafikat ega segavorme, vastasel juhul võib see põhjustada tõrke või väljund võib olla vale.
Vastus:
Otsige OCR-i teostamiseks dokumendist tekstiversioon. Võimalik, et peate tegema ka graafika ja kujundite abil dokumendituvastuse, kui see toimib, peate võib-olla väljundis parandusi tegema.
Mis on OCR Adobe Acrobatis?
OCR on protsess, mille käigus Acrobat kinnitab piksliga teksti või pilte. Iga märk tuvastatakse ja teisendatakse tekstiks. Acrobat võrdleb pildi kuju ja joone paksust OCR-i ajal teie arvutisse juba installitud fontidega. Järgmised on OCR-i skannimise vea põhjused.
Milline failivorming OCR-i jaoks ei sobi?
JPEG-failivormingut ei ole OCR-i jaoks kõige parem salvestada, kuna JPEG kipub oma kvaliteeti kaotama iga kord, kui see salvestatakse. Isegi kui teisendate JPEG-i PDF-vormingusse, võib see ikkagi olla halva kvaliteediga. Parim on salvestada oma dokumendid PDF- või TIFF-vormingus, kui kavatsete neid märgituvastust teostada.